前言
这篇文章总结了我学习字符编码的学习笔记。
引言
无论你是搞前端,后端,还是移动,ios,只要在开发,或者说,只要你在使用计算机,那么就不可能避开字符编码的问题。
比如经典的烫烫烫烫这个梗,就是访问数组越界了,在 c 里的话,会给一个脏值,即值不确定的数。而在 Visual Studio 中,如果程序是 GB 系列的编码,debug 模式下会给未初始化的栈空间用 0xCC 填充,就是 ‘烫’ 字,而未初始化的堆空间则会用 0xCD 填充,这就是 ‘屯’ 字。如果输出的时候没有 '\0' 的话,就是一直打印,所以这就是这个著名的 烫烫烫烫烫烫 梗的来源了。如果你更改编码,换成台湾(BIG-5)的编码,则会变成,“昍昍昍”,如果是日本(Shift-JIS)应该会显示 “フフフフフフ”。当然这也是多种巧合重合才出现了这种结果,如果你换一个 ide,或者在 Linux 下编译的话,则会报段错误,原因是 Linux 不支持访问越界的内存。
数据类型的由来
计算机都是 0,1 组成的,这是由硬件结构所决定的,这是我们都知道的。那么我们为什么要封装 data type 这个概念呢?当我们在说可执行文件,文本文件,int,character 的时候,我们究竟在说些什么?它们不都是 0 和 1 吗,它们有什么区别?
在任何一个高级语言中,你总能发现它们拥有一些相同的数据类型。number, character,bool,point, null 等。而又有其他基于此的类型,如 map,string,array 等等。
问题来了,为什么我们要这么做?
在 sicp 这本书中,它一直在强调一点,那就是抽象的重要性。而这里,其实也是抽象后,封装的一种思想。
a type is a combination of data, and the operations you can perform on the data.
这是 stackoverflow 上一位答主回答提问者的答案,这是什么意思呢?
type 是 data 和对 data 操作的封装。
我们来缕缕这是什么意思,我们抽象出 int 类型,这种 type 是数字中,整数的集合。然后我们同时也定义了对 int 的操作,如 1+1, 1-2 这样的操作,即 +, -, *, /,% 等操作。
现在我们再来看 int type,我们封装了 int 和它的 operations, 那么我们是怎么封装的,比如我们操作 1+1 的时候,计算机做了些什么?都是 0 和 1, 那么这些 0,1 间发生了什么?
如果我们对 number 这种 type 还有一点印象的话,我们会发现,计算机对 number 还分为了许多不同的类型。如 signed , unsigned, int, float 等。当我们写 1.23 的时候,计算机是怎么表示这个数的,我们就需要学到计算机是怎么存 number 类型的。当我们进行 1+1,对 number 操作时,我们还需要学习计算机是怎么操作 number 的。
这里对 float 的存储和操作的封装就有一些坑,比如 go 中 float64 的 110.32 加 10.86 会等于 *121.17999999999999*,而不是 121.18。
func main() {
var num1, num2 float64
num1 = 110.32
num2 = 10.86
fmt.Println(num1 + num2) // 121.17999999999999
}
这就必须要知道计算机是怎么封装 float 才能理解,不然我们是无法理解这一点的。而在大名鼎鼎的 csapp 中,也专门拿了一章节来讲解这一点,可见其影响之广。
当我们有了上面对 float 封装的这种思想后,我们再来看看 bool type,我们将现实世界中的 真 和 假 这两个概念封装进了计算机,并且对它们的操作,如对其中一个取反会得到另一个值。那么计算机又是怎么封装这些操作的呢?当我们使用 a = false 的时候,计算机究竟发生了些什么?
这里就不深入分析了,重点是想引入 type 封装的这种思想,当有了这种思想,以后再深入底层时,会对整体框架根据清晰。而对于这些 type 的封装,有一门学科叫 type system 就是专门讲这方面的,而要深入一门语言的学习的话,都会了解到这方面的。
现在我们继续深入今天的重点,character。
我们再来记忆一下对 type 封装的原则:type 是 data 和对 data 操作的封装。
那么 character 是什么呢?我们这里先不深入,我们来看一下对 char 的操作,回想一下我们平时操作 char 干什么来着,好像就是打印,表示特殊的含义,也没有 + 这种操作,当然在 c 中或 go 里都能这么做,但这是编码的问题,而不是封装的性质。
func main() {
b := 'a' + 'b'
fmt.Println(b) // 195
}
可以思考一下,为什么会是 195?
在继续往下面深入前,我们先来思考一个问题,明明我们已经封装了 number 这种类型,为什么 character 中还有数字字符?
int main(void) {
printf("%d", '1');
return 0;
}
或者说再问一个问题,一个文件也就是一些 0,1 组成的。当我们给一个文件选择一种编码方式时,如果文件中有数字,那么是如果知道这些数字表示是 number 类型,还是字符类型呢?如果不是字符类型,怎么对其进行字符判断。
可能你猜到了,文本文件中只有数字字符,没有数字类型。
在 c 中,往文件中写入数据的两个函数
int fputc( int c, FILE *fp );
int fputs( const char *s, FILE *fp );
fputc 把字符 c 存到文件 fp 中, 而 fputs 把 char array s 存到 fp 中。
可能你会问,c 不是 int 类型吗?
int main(void) {
FILE *fp = fopen("a.txt", "w+");
fputc('a', fp); // 'a'
fclose(fp);
return 0;
}
int main(void) {
FILE *fp = fopen("a.txt", "w+");
fputc("a", fp); // null
fclose(fp);
return 0;
}
int main(void) {
FILE *fp = fopen("a.txt", "w+");
fputc(123, fp); // {
fclose(fp);
return 0;
}
可以执行一下这几个函数看看。我们明明传的 123, 为什么文件中存入了 {, 这也是这个问题的答案,为什么 char 可以 + 或 -?
这里先不解释。我们先回答上一个问题,即为何 char 中有 number char,这是因为在存储,传输过程中都是 char,而不是 number 类型。所以打印在屏幕上的 1,其实是 char 类型,而不是 number 类型。
有了这些前置知识后,我们终于可以来进入今天的重点了,那就是,计算机是怎么识别 char 的?字符编码究竟是怎么一回事?
character
说了半天字符编码,那么字符 char 究竟是个什么玩意,为什么计算机要封装这个东西呢?
a character is a unit of information
wiki 的解释非常简洁,char 是信息的基本单位。
人类使用自然语言交流,而语言是一些符号组成,我们对这些符号赋予意义,然后符号进行组合表达出我们想要表达的意思。
比如我们使用汉语中的 我 这个字符来表示说话的这个个体。同样在英语中,字符 i 也代表说话的这个个体。我这段话,这篇文章,都是一些字符组合后形成的。
character 是一个信息单位。可以是已经存在的,如在自然语言中,对应于汉字,字母,数字,或者标点符号等,也可以是不存在,而为了使用而创建的,如空字符,空白字符等等在特殊场景使用的。
字符是一种符号的抽象。我们前面说过,抽象的这个概念,其实 char 也是一个比较抽象的概念。我们会说汉字 我 是一个字符,但很少会说笔画 横线 是一个字符。但是,如果我们使用五笔输入法的话,会发现笔画其实也可以抽象为一种字符。所以字符的定义是看我们的定义的,只要能作为信息的基本单位,我们就可以称为一个字符,而信息总是不定的,所以字符也不一定是历史中出现的,比如控制字符 \r 就是因为打印机的发明才出现的字符,而以前是没有这个概念的。
字符没有特定的形状。没有特定的形状,但是我们却可以识别出来,这其实是一个非常有意思的问题。比如现在给一只黑色的马,和一只白色的马,但是我们都能称它为马,但是如果问你,马 是什么,你可能便无法回答了。同样的,字符也没有特定的形状,一个人写的字符和另一个人写的字符肯定有区别,但是我们却能明白它们都表示的是一个字符,这在哲学上其实也是一个很有意思的问题,有人就认为一定存在一个东西表示 马,而我们才会认为各种东西像它,那么这个东西是什么,它存在在什么地方等,都是一个有意思的问题。当然我相信认知科学上对这些东西会有相关的研究,这里就不展开了。
字符有应用场景。字符不是我们没事随便发明的,而是在特定的应用场景中诞生的,所以字符一般都有其特定的使用场景,要看一个字符有什么意思的话,需要看字符所在的上下文,不仅一门语言中字符可能有不同的意思,而且不同语言中可能也会产生相同的字符,比如数学中的 π 代表的是一个数字,而在希腊语言中,它又是组成希腊语言的一个字符。
字符编码的历史
学习一样东西从它的发展历史上着手是一个很好的办法,谈到字符编码的话,会有各种各样的名词,比如 ASCII, Unicode, ANSI, GBK 等等,它们表示什么意思,它们又在历史中扮演着怎样的地位,让我们来跟着历史演变一遍吧。
古代的通信方式
很久很久以前,人们之间的长途通讯主要是用信鸽、骑马送报、烽烟等方式进行。
世界第一条电报
直到 1837 年,世界第一条电报诞生,当时美国科学家莫尔斯尝试用一些 “点” 和 “划” 来表示不同的字母、数字和标点符号,这套表示字符的方式也被称为 “摩尔斯电码”。
世界第一台计算机
再后来到了 1946 年,世界第一台计算机诞生。发明计算机的同学们用 8 个晶体管的 “通” 或 “断” 组合出一些状态来表示世间万物,不过当时的计算机有一间半教室那么大,六头大象重,从现在看来这简直就是个怪物,但在当时却是震惊世界与改变世界的一项重要发明。
EBCDIC
1964, IBM 推出 EBCDIC 编码标准,EBCDIC,是 Extended Binary Coded Decimal Interchange Code (即扩展二进制编码的十进制交换码) 的缩写。这是世界上最早的字符编码标准。
EBCDIC(英语:Extended Binary Coded Decimal Interchange Code,扩增二进式十进交换码),为 IBM 于 1963 年-1964 年间推出的字元编码表,根据早期 打孔机式的二进化十进数( *BCD*,*Binary Coded Decimal*)排列而成。是 IBM 迷尔级以上电脑的标准码。
它的缺点是:英文字母不是连续地排列,中间出现多次断续,为撰写程式的人带来了一些困难。
EBCDIC 是 IBM 根据打孔机搞出来的一个编码,长这个样子。
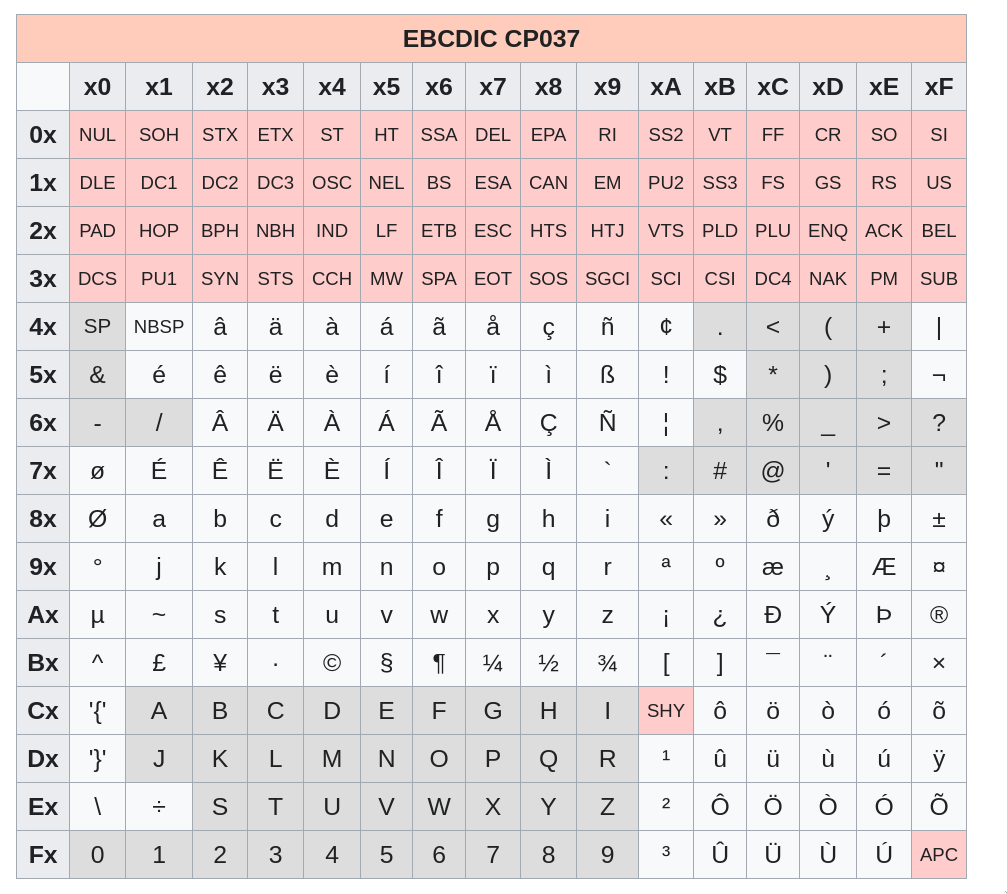
可以看到的确英文字符是分割开的,这很不方便,注意计算机是在美国发明的,而 IBM 也是美国公司,所以上面的字符的确都是拉丁字符。
ASCII
1968 年,美国国家标准学会 ANSI (American National Standard Institute) 根据电报码发明了 ASCII (American Standard Code for Information Interchange 美国信息交换标准码)。
ASCII 的设计吸取了 EBCDIC 的发布教训使,把英文字符重新进行了排序,这更有利于程序的处理。
同时需要注意,ASCII 也是美国提出来的,所以也只有拉丁字符。
最早的版本长这个样子。
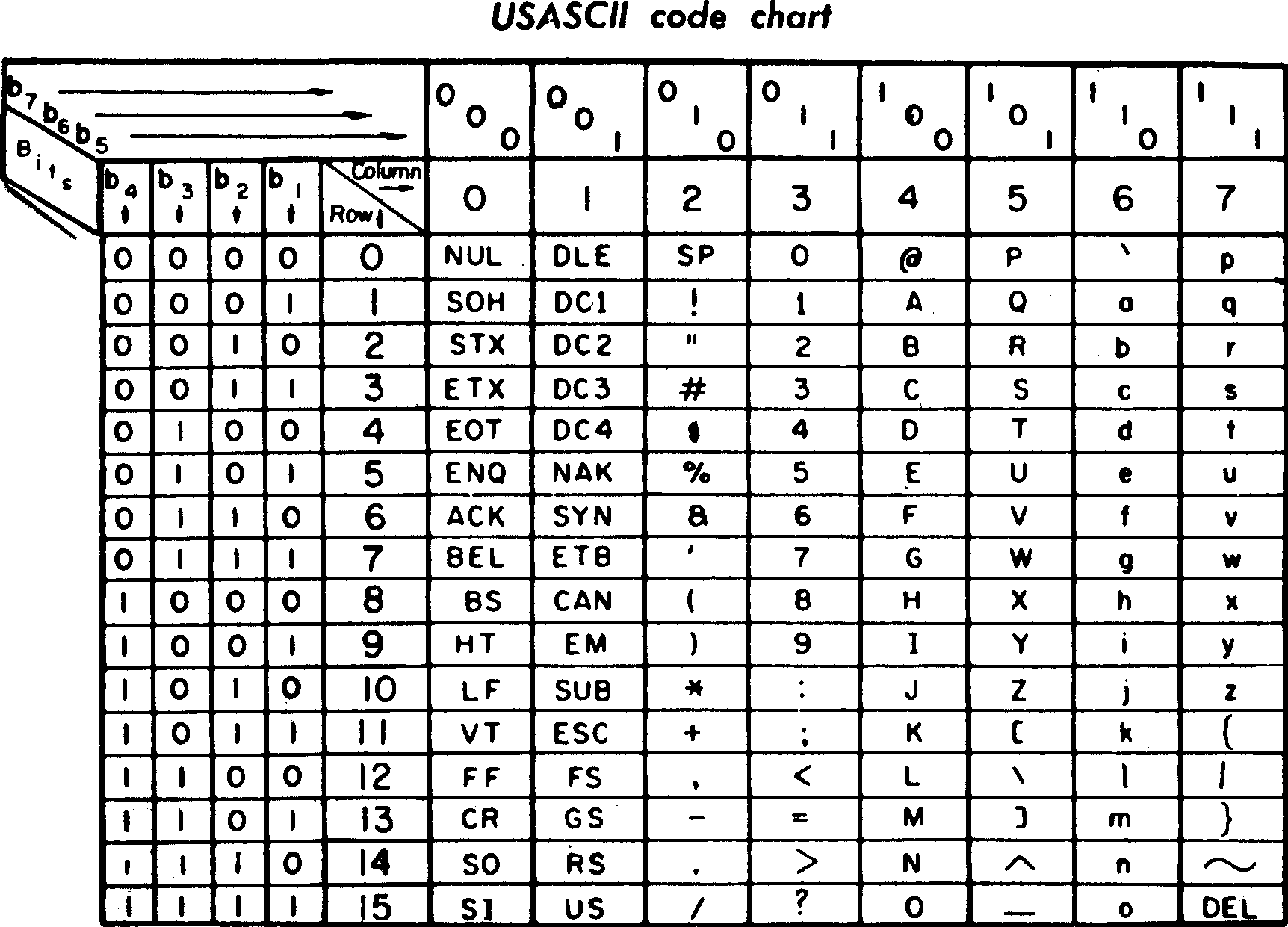
ASCII 字符至今为止也是最基础、最重要、应用最广泛的字符编码方案。之后的编码方案多少几乎都兼容这个方案。
ISO/IEC 646
1946 年, ISO,即国际标准化组织 International Standardization Organization 登上历史舞台。
1906 年,IEC,即国际电工技术委员会 International Electrotechnical Commission 也登上历史舞台。
ISO/IEC 往往用来表示由这两大国际组织联合制定的标准。
1972, ISO/IEC 发布 ISO/IEC 646 标准,主要参考欧洲的那些国家,它们都使用的拉丁字符,所以主要参考 ASCII, 现在几乎和 ASCII 标准是同义词了。
ISO 646 长这样
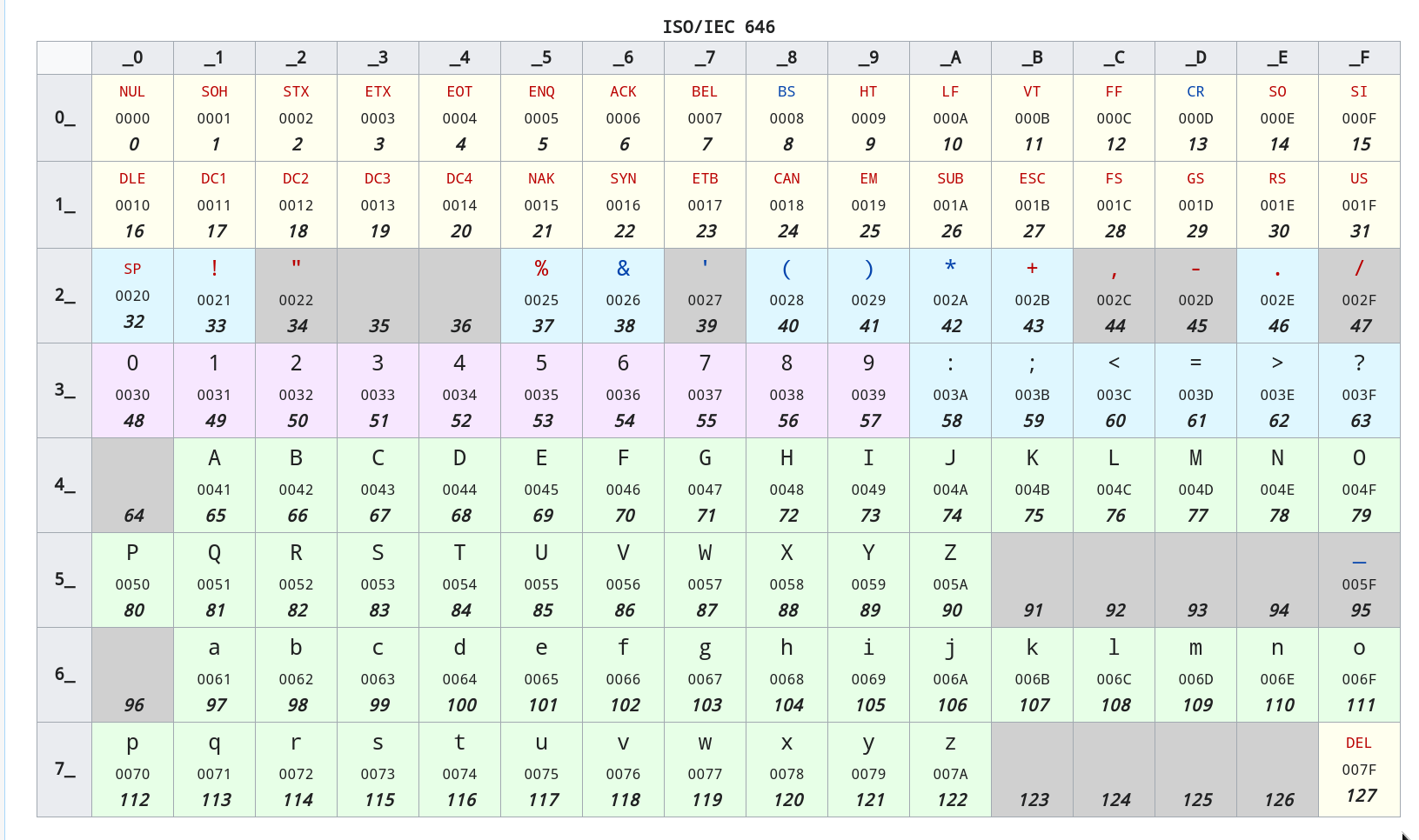
ANSI
计算机在美国发明,后来计算机开始发展到其他各个国家,但是美国的 ASCII 标准显然只有拉丁字符,而其他各个国家的字符是无法显示的,所以各个国家都制定了一些自己的标准,因为 ASCII 的特殊性,所以这些标准一般都兼容 ASCII 字符,但是相互之间却不兼容。
计算机首先逐渐从美国发展到了欧洲。各国就开始分别扩展 ASCII 字符,统称为 EASCII(Extended ASCII,延伸美国标准信息交换码)。
但是不同国家使用不同的标准,这显然会出现兼容问题,所以 ISO/IEC 又出现了,它制定了一系列的标准。便于欧洲各种的使用。这个标准集统称为 ISO/IEC 8859。
ISO/IEC 8859 是一系列标准的统称,所以又有 ISO/IEC 8859-n,n=1、2、3…15、16 (其中 12 未定义,所以共 15 个) 这个写法。
ISO/IEC 8859-1 (Latin-1) - 西欧语言
ISO/IEC 8859-2 (Latin-2) - 中欧语言
ISO/IEC 8859-3 (Latin-3) - 南欧语言。世界语也可用此字符集显示。
ISO/IEC 8859-4 (Latin-4) - 北欧语言
ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
ISO/IEC 8859-6 (Arabic) - 阿拉伯语
ISO/IEC 8859-7 (Greek) - 希腊语
ISO/IEC 8859-8 (Hebrew) - 希伯来语(视觉顺序)
ISO 8859-8-I - 希伯来语(逻辑顺序)
ISO/IEC 8859-9(Latin-5 或 Turkish)- 它把 Latin-1 的 冰岛语字母换走,加入土耳其语字母。
ISO/IEC 8859-10(Latin-6 或 Nordic)- 北日耳曼语支,用来代替 Latin-4。
ISO/IEC 8859-11 (Thai) - 泰语,从泰国的 TIS620 标准字集演化而来。
ISO/IEC 8859-13(Latin-7 或 Baltic Rim)- 波罗的语族
ISO/IEC 8859-14(Latin-8 或 Celtic)- 凯尔特语族
ISO/IEC 8859-15 (Latin-9) - 西欧语言,加入 Latin-1 欠缺的 芬兰语字母和大写法语重音字母,以及欧元(€)符号。
ISO/IEC 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
后来计算机发展到中国,中国自然也制定了许多响应的标准。这些标准被称为 GB 系列编码。(“GB” 为 “国标” 的汉语拼音首字母缩写,即 “国家标准” 之意)
同样的,GB 系列也是兼容 ASCII 字符的。
最早的 GB 编码方案是 GB2312,收录的汉字不足一万个,基本能满足日常使用需求,但不包含一些生僻字,对于人名、古汉语等方面出现的罕用字、生僻字,GB2312 不能处理,如部分在 GB2312-1980 推出以后才简化的汉字 (如 “啰”)、部分人名用字 (如歌手陶喆的 “喆” 字)、台湾及香港使用的繁体字、日语及朝鲜语汉字等,并未收录在内。因此后来又在 GB2312 基础上进行了扩展。
在 GB2312 基础上扩展的编码方案称之为 GBK (K 为 “扩展” 的拼音首字母)。
后来又在 GBK 的基础上进一步扩展,称之为 GB18030,加入了一些国内少数民族的文字。
包括 GB2312、GBK、GB18030 在内的 GB 系列编码方案 ,每扩展一次都完全保留之前版本的编码,所以每个新版本都向下兼容。
这里解释一下 全角、半角 这两个名词:
全角字符是中文显示及双字节中文编码的历史遗留问题。
早期的点阵显示器上由于像素有限,原先 ASCII 西文字符的显示宽度 (比如 8 像素的宽度) 用来显示汉字有些捉襟见肘 (实际上早期的针式打印机在打印输出时也存在这个问题),因此就采用了两倍于 ASCII 字符的显示宽度 (比如 16 像素的宽度) 来显示汉字。
这样一来,ASCII 西文字符在显示时其宽度为汉字的一半。或许是为了在西文字符与汉字混合排版时,让西文字符能与汉字对齐等视觉美观上的考虑,于是就设计了让西文字母、数字和标点等特殊字符在外观视觉上也占用一个汉字的视觉空间 (主要是宽度),并且在内部存储上也同汉字一样使用 2 个字节进行存储的方案。这些与汉字在显示宽度上一样的西文字符就被称之为全角字符。
而原来 ASCII 中的西文字符由于在外观视觉上仅占用半个汉字的视觉空间 (主要是宽度),并且在内部存储上使用 1 个字节进行存储,相对于全角字符,因而被称之为半角字符。
后来,其中的一些全角字符因为比较有用,就得到了广泛应用 (比如全角的逗号 “,”、问号 “?”、感叹号 “!”、空格 “ ” 等,这些字符在输入法中文输入状态下的半角与全角是一样的,英文输入状态下全角跟中文输入状态一样,但半角大约为全角的二分之一宽),专用于中日韩文本,成为了标准的中日韩标点字符。而其它的许多全角字符则逐渐失去了价值 (现在很少需要让纯文本的中文和西文字符对齐了),就很少再用了。
现在全球字符编码的事实标准是 Unicode 字符集及基于此的 UTF-8、UTF-16 等编码实现方式。Unicode 吸纳了许多遗留 (legacy) 编码,并且为了兼容性而保留了所有字符。因此中文编码方案中的这些全角字符也保留下来了,而国家标准也仍要求字体和软件都支持这些全角字符。
不过,半角和全角字符的关系在 UTF-8、UTF-16 等中不再是简单的 1 字节和 2 字节的关系了。具体参见后文。
当计算机发展到日本后,也出现了 Shift JIS 编码标准,而在台湾,大概是因为早期的 GB2312 编码没有繁体,所以台湾也指定了编码标准 Big5,而在韩国,也有 KS X 标准。
同样的,计算机发展到其他国家后也出现了相应的标准,需要注意的是,这些标准的兼容 ASCII。
但是随着科技的发展,国家与国家间的交流越发频繁,国家交流是一个迈不过去的坎。这时,一个能兼容所有国家的标准就应运而生了。
Unicode/UCS
最初,由世界上多家多语言软件开发商组成了统一码联盟 (The Unicode Consortium),接着于 1991 年发布了 The Unicode Standard (统一码标准),定义了一个全球统一的通用字符集,习惯简称为 Unicode 字符集。
接着,ISO 及 IEC 也于 1993 年联合发布了一个标准号为 ISO/IEC 10646-1 的全球统一的通用字符集,称之为 Universal Multiple-Octet Coded Character Set ,简称为 Universal Character Set (即通用字符集,缩写为 UCS)。
后来,统一码联盟与 ISO/IEC 双方都意识到世界上没有必要存在两套全球统一的通用字符集,于是两者开始合作,共同为创立一个单一的全球统一的通用字符集而协同工作。到了 Unicode 2.0 标准发布时,Unicode 字符集和 UCS 字符集 (即 ISO/IEC 10646-1) 基本保持了一致。
虽然现在这两个标准仍然独立存在,但统一码联盟和 ISO/IEC 都同意保持两者的通用字符集相互兼容,并共同调整未来的任何扩展。
目前,Unicode 的知名度要比 UCS 大得多,实践中的应用也更为广泛得多,已成为了全球统一的通用字符集或编码方案的代名词。因此,Unicode 字符编码方案已经成为了全球统一字符编码方案事实上的标准。
这里有人可能会问,UTF-8, UTF-16 又是什么东西呢?它们在历史中又扮演了怎样的地位。这里就要引入现代编码体系了。
The Character Encoding Model
2008-11-11 年,Unicode Technical Report 提出 Unicode Character Encoding Model(现代编码模型)。
现代编码模型一共把字符编码分为了五层。即 ACR,CCS,CEF,CES,TES。
Abstract Character Repertoire
Abstract Character Repertoire 也被称为 character set, 也就是字符的集合。
抽象字符表 ACR 是一个编码系统支持的所有抽象字符的集合,可以简单理解为无序的字符集合,用于确定字符的范围,即要支持哪些字符。
抽象字符表 ACR 的一个重要特点是字符的无序性,即其中的字符并没有编排数字顺序,当然也就没有数字编号。
“抽象” 字符不具有某种特定的字形,不应与具有某种特定字形的 “具体” 字符混淆。
字符表可以是封闭的 (即字符范围是固定的),即除非创建一个新的标准,否则 不允许添加新的字符,比如 ASCII 字符表和 ISO/IEC 8859 系列都是这样的例子;字符表也可以是开放的 (即字符范围是不固定的),即 允许不断添加新的字符,比如 Unicode 字符表和一定程度上 Code Page 代码页 (代码页后文会有详细解释) 是这方面的例子。
character set 是一个 set,一些不重合的 charater 被称为 charater set,如 26 个英文字母是一个 set,所有汉字是一个 set 等。
如 {‘1’,’2’,’3’,’4’,’5’} 是一个 set,如 {‘a’,’b’,’c’} 是一个 set
Coded Character Set
前面讲了,抽象字符表里的字符是没有编排顺序的,但无序的抽象字符表只能判断某个字符是否属于某个字符表,却无法方便地引用、指称该字符表中的某个特定字符。
为了更方便地引用、指称字符表中的字符,就必须为抽象字符表中的每个字符进行编号。
所谓字符编号,就是将抽象字符表 ACR 中的每个抽象字符 (简称字符) 表示为 1 个非负整数 N 或者映射到 1 个坐标 (非负整数值对 x, y),也就是将抽象字符的集合映射到一个非负整数或非负整数值对的集合,映射的结果就是编号字符集 CCS。因此,字符的编号也就是字符的非负整数代码。
例如,在一个给定的抽象字符表中,表示大写拉丁字母 “A” 的字符被赋予非负整数 65、字符 “B” 是 66,如此继续下去。
由此产生了编号空间 (Code Space,一般翻译为代码空间、码空间、码点空间) 的概念:根据抽象字符表中抽象字符的数目,可以设定一个字符编号的上限值 (该上限值往往设定为大于抽象字符表中的字符总数),从 0 到该上限值之间的非负整数范围就称之为编号空间。
编号空间的描述:
1)可以用一对非负整数来描述,例如:GB2312 的汉字编号空间是 94 x 94;
2)也可以用一个非负整数来描述,例如:ISO-8859-1 的编号空间是 256;
3)也可以用字符的存储单元尺寸来描述,例如:ISO-8859-1 是一个 8 比特的编号空间 (2^8=256);
4)还可以用其子集来描述,如行、列、面 (Plane 平面、层面) 等等。
编号空间中的一个位置 (Position) 称为码点 (Code Point 代码点) 或 码位 (Code Position 代码位)。一个字符占用的码点所在的坐标 (非负整数值对) 或所代表的非负整数,就是该字符的编号,又称之为 码点值 (即码点编号)。
不过,严格来讲,字符编号并不完全等同于码点编号 (即码点值)。因为事实上,由于某些特殊的原因,编号字符集 CCS 里的码点数量要大于抽象字符表 ACR 中的字符数量。
在编号字符集中,除了字符码点之外,还存在着非字符码点和保留码点,所以字符编号不如码点编号准确;但若对字符码点的码点编号称之为字符编号,倒也更为直接。
在 Unicode 编码方案中,字符码点又称之为 Unicode 标量值 (Unicode Scalar Value,感觉不如字符码点更为直观),非字符码点和保留码点详见后文介绍。
ASCII 和 Unicode
code point
我们知道计算机只能处理数字,那么计算机是怎么处理字符的呢?
简单,我们把每个字符映射到一个特定的数字上,操作这个数字来表示操作这个字符。这个数字就被称为码点(code point)
code space
the range of code point
ASCII 中就是简单的 0 ~ 127, 而 GB 系列中则是区位码(坐标)。
编码空间表示字符映射到数字的集合,也包含所有字符。
Character Encoding Scheme
code unit
A code unit is the unit of storage of a part of an encoded code point. In UTF-8 this means 8-bits, in UTF-16 this means 16-bits. A single code unit may represent a full code point, or part of a code point. For example, the snowman glyph (
☃) is a single code point but 3 UTF-8 code units, and 1 UTF-16 code unit
字符编码方式 CEF,是将编号字符集里字符的 码点值 (即码点编号、字符编号) 转换成或者说编码成有限比特长度的 编码值 (即字符编码)。该编码值实际上是 码元 (Code Unit 代码单元、编码单元) 的序列 (Code Unit Sequence)。
那什么是码元呢?为什么要引入码元这个概念呢?字符集里的字符编号 (即码点值、码点编号) 又是如何转换为计算机中的 字符编码 (即码元序列) 的呢?别急,这里先记下这个概念,暂不深究,后文有详细解释。
字符编码方式 CEF 也被称为 “存储格式”(Storage Format)。不过,将 CEF 称之为存储格式实际上并不合理,因为 CEF 还只是逻辑层面上的、与特定的计算机系统平台无关的编码方式,尚未涉及到物理层面上的、与特定的计算机系统平台相关的存储方式 (第 4 层才涉及到)。
在 ASCII 这样传统的、简单的字符编码系统中,并没有也不需要区分字符编号与字符编码,可认为字符编号就是字符编码,字符编号与字符编码之间是一个直接映射的关系。
而在 Unicode 这样现代的、复杂的字符编码系统中,则必须区分字符编号与字符编码,字符编号不一定等于字符编码,字符编号与字符编码之间不一定是一个直接映射的关系,比如 UTF-8、UTF-16 为间接映射,而 UTF-32 则为直接映射。
UTF-8、UTF-16 与 UTF-32 等就是 Unicode 字符集 (即编号字符集) 常用的字符编码方式 CEF。(UTF-8、UTF-16 与 UTF-32 后文各有详细介绍)
Character Encoding Form
Transfer Encoding Syntax
code unit
Linux 系统编码
输入 locale 可以查看系统本地的一些设置
$ locale | grep LANG
LANG=en_US.UTF-8
这里可以看到,前面的 en_US 意思是系统语言是英文的,而使用的字符集是 Unicode, 编码方式则是 UTF-8.
字符编码
ASCII
GB
http://tools.jb51.net/table/gbk_table
UTF-8/UTF-16/UTF-32
http://www.tamasoft.co.jp/en/general-info/index.html
实际应用
文件编码
Jetbrains 编码
go 编码
go 默认为 UTF-8 编码。
gzip
http 传输中常对传输的数据进行压缩,gzip 就是一种常见的压缩算法。
mysql
总结
什么是字符集?
什么是字符编码?
字符集、字符编码与字体(字型)之间的辨析?
常见的字符集及字符编码有哪些?
每一种字符编码的特点是什么?
Unicode 编码的 BOM 是什么?它和 UTF-8 有什么关系?
Windows 自带记事本中的几种编码格式分别代表什么意思?(了解这一点才方便你深入的、有理有据的黑记事本,同时坚定的换用其它文本编辑器)
在程序代码里声明编码格式和程序文件本身的编码格式有什么联系和区别(尤其对于 html 文件来说这一点尤为主要)?
HTTP 请求头和响应头里关于文件编码的内容有哪些,分别代表什么意思?
参考
If characters can hold what integers can then why is there a need to use integers?